Table of Contents
What Is Matryoshka Representation Learning? How Gemini Embedding 2 Improves AI Efficiency
Let’s talk about something beautiful hiding inside something else. You know those Russian nesting dolls? The ones where you open one, and there’s another, and another, each perfectly sized to fit inside the last? That’s not just a charming toy—it’s the blueprint for the next leap in AI efficiency.
Welcome to the era of Matryoshka Representation Learning (MRL). If you work with AI—building search, RAG pipelines, or semantic systems—you’re going to want to pay attention. Because the latest updates from Google, Anthropic, OpenAI, and Perplexity aren’t just incremental tweaks. They’re a coordinated shift toward smarter, leaner, more adaptable intelligence.
And it all starts with a simple idea: what if your AI embeddings could be flexible? What if they could shrink or expand based on the task, without losing their core meaning? That’s exactly what Gemini Embedding 2 delivers. And it changes everything about how we think about vector storage, retrieval speed, and cost.
The Gemini Embedding 2 Breakthrough: Flexibility Without Compromise
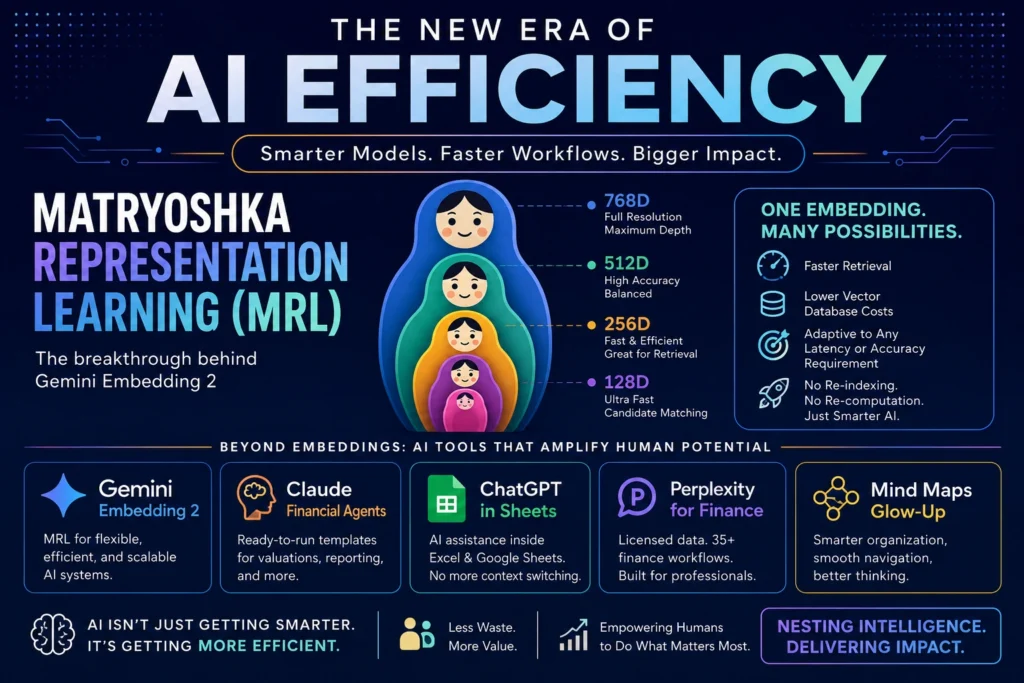
Google’s Gemini Embedding 2 isn’t just another model drop. It’s a fundamental rethinking of how vector representations work. At its heart is Matryoshka Representation Learning (MRL), a technique that lets embeddings carry multiple levels of detail in a single structure. Think of it like nested intelligence, ready to adapt on demand.
Traditional embeddings are like a single, fixed-size photograph. You take it, you store it, you use it. But if you need a thumbnail? You crop it, and you lose detail. MRL embeddings are different—they’re like a set of nested photos, each one complete at its own resolution. You choose the right layer for the job.
You can use the full-resolution version for high-stakes analysis. Or you can pull out just the inner core for lightning-fast candidate matching. And here’s the magic: you don’t lose precision when you truncate. The model is trained to preserve semantic meaning at every layer of the “doll.”
So you get speed when you need it, and depth when you demand it. This isn’t theoretical—it’s practical, immediate, and cost-saving. Let’s break down the three big wins that make MRL a game-changer for real-world AI systems.
First: dynamic vector truncation for high-speed matching. In semantic search or RAG, you often start with a broad candidate pool. You don’t need the full 768-dimensional vector to do that first pass. With MRL, you can use a 128-dimensional slice for initial filtering—faster, cheaper, and just as accurate for that stage.
Then, for the final ranking, you expand to the full vector. No re-computation. No re-indexing. Just smart, adaptive retrieval that matches your workflow. That’s a massive operational win for teams managing large-scale search or recommendation systems.
Second: slash your database costs. Vector databases charge by storage and compute. Full-size embeddings eat space. With MRL, you choose your storage footprint upfront. Need to cut costs by 50%? Store the mid-layer vectors. Your system still works. Your accuracy stays high. And you never have to re-index your entire corpus.
Third: adapt to any latency or accuracy requirement. Every application has different needs. A mobile app needs sub-100ms responses. A research tool can afford a few extra seconds for deeper analysis. MRL lets you tune the same embedding to both. You’re not locked into one trade-off—you get a spectrum of performance from a single model.
Why This Matters for RAG and Semantic Search
If you’re building retrieval-augmented generation (RAG) systems, this is huge. RAG lives or dies by retrieval quality and speed. Too slow, and users bounce. Too shallow, and answers are generic or wrong. MRL solves both problems elegantly with adaptive vector usage.
Imagine your RAG pipeline. A user asks a complex question. First, you do a broad semantic sweep using truncated vectors. You pull 100 candidate documents in milliseconds. Then, for the top 20, you expand to full vectors for precise re-ranking. Finally, you feed the top 5 to your LLM for answer generation.
Each stage uses the right level of detail. No wasted compute. No compromised accuracy. And because you’re not storing multiple copies of embeddings, your vector DB stays lean. This isn’t just optimization—it’s a new architecture pattern that scales gracefully as your data grows.
Semantic search gets the same boost. E-commerce sites can filter millions of products instantly. Support teams can find relevant tickets without lag. Researchers can explore literature with fluid, responsive queries. The key is adaptability—and MRL makes adaptability native to the embedding itself.
Real-World Impact: Cost, Speed, and Developer Experience
Let’s talk numbers, because they matter. Early benchmarks show MRL-based systems can reduce vector storage by 40-60%. That directly lowers your cloud bill. Latency for initial retrieval drops by 3-5x with truncated vectors. That means happier users and higher engagement across your platform.
And developer experience? It’s smoother. You’re not managing multiple embedding models for different tasks. One model, multiple use cases. You’re not re-indexing when requirements change—just adjust the truncation point in your query logic. That agility is priceless in fast-moving teams.
Plus, MRL plays nice with existing infrastructure. You don’t need a new vector database. You don’t need to rewrite your retrieval logic. You just start using the flexible vectors Gemini Embedding 2 provides. It’s an upgrade, not an overhaul—and in enterprise environments, that’s the difference between adoption and abandonment.
Mind Maps Get a Major Glow-Up 💅
Now, let’s shift gears to something more visual. Mind mapping tools are getting a serious refresh—and it’s not just about prettier interfaces. It’s about making complex thinking more fluid, more collaborative, and more actionable for teams everywhere.
The new features rolling out today focus on three pillars: customization, organization, and navigation. First: customization. You can now steer your mind map with specific user prompts. Instead of starting from a blank node, you tell the system what you’re exploring. The AI generates a structured starting point, tailored to your goal.
Second: organization. Rename and share your maps instantly. No more “Untitled Map (17)” cluttering your workspace. Give your maps clear, descriptive titles. Share them with teammates via link or embed. Permissions are granular, so you control who can view or edit—turning mind maps from personal scratchpads into team assets.
Third: navigation. Silky smooth transitions between nodes. Zoom, pan, and drill down without lag or disorientation. It feels like exploring a living document, not clicking through static boxes. And for large, complex maps, that fluidity is essential. You can hold the big picture while diving into details—that’s how breakthroughs happen.
Claude Agents for Financial Services: Ready-to-Run Templates
Now, let’s talk finance. Because if you work in financial services, time is money. And repetitive tasks? They’re profit leaks. Anthropic just dropped a suite of ready-to-run Claude agent templates built specifically for finance teams—and they’re designed to slot into your existing process.
These aren’t generic prompts. They’re full-featured agents with connectors, skills, and sub-agents pre-wired for real workflows. Think: building investor pitches, conducting valuation reviews, closing the books at month-end. Each template is designed to slot into your existing process with minimal setup.
You can install them as plugins in Cowork or Claude Code. Or use the provided cookbooks to run them in production as Managed Agents. That flexibility is key. Start small with a pilot. Scale to enterprise deployment when you’re ready—and because they’re built on Claude, they bring strong reasoning to complex financial tasks.
Let’s unpack one example: the valuation review agent. It can pull data from your internal systems. Cross-reference with market benchmarks. Flag inconsistencies or outliers. Draft a summary for senior review—all while citing sources and maintaining an audit trail. That’s not just automation. That’s augmentation.
Another template: month-end close. It can reconcile accounts, validate entries, and generate compliance reports. It knows the difference between a timing difference and an error. And it asks for human input when something’s ambiguous. That’s the sweet spot: AI handling the routine, humans handling the exceptional.
ChatGPT Comes to Your Spreadsheet: No More Context Switching
Here’s a game-changer for anyone who lives in Excel or Google Sheets. ChatGPT is now available as an add-on in both platforms. That means you can get AI help without ever leaving your spreadsheet—analyze messy data, write complex formulas, update ranges dynamically, and explain what it’s doing along the way.
No more black-box magic. You see the logic, step by step. That builds trust and accelerates learning. Imagine you’ve got a dataset with inconsistent formatting. Instead of spending hours cleaning it manually, you ask ChatGPT: “Standardize the date columns and flag duplicates.” It does it, and shows you the formula it used.
Or you’re building a financial model. You can ask: “Create a sensitivity table for revenue under three growth scenarios.” ChatGPT writes the formulas, sets up the table, and labels everything clearly. You tweak the assumptions, and the model updates. This isn’t just about convenience—it’s about democratizing advanced analysis.
And because it’s powered by GPT-5, the reasoning is sharp. It understands financial logic, statistical concepts, and business context. It can even spot potential errors in your logic and suggest corrections. That’s like having a senior analyst looking over your shoulder—but available 24/7, at no extra headcount cost.
Perplexity Computer for Professional Finance: Licensed Data Meets AI Workflows
Perplexity is making a serious play for finance teams. They just launched Perplexity Computer for Professional Finance—and it’s built for the unique demands of financial analysis. First, it brings licensed data directly into the AI workspace: Morningstar, PitchBook, Daloopa, and Carbon Arc.
That means you’re not just getting AI-generated insights. You’re getting insights grounded in authoritative, up-to-date financial data. No more cross-referencing three different platforms. No more worrying about data freshness or licensing compliance. It’s all in one place, ready for analysis.
Second, they’ve added 35 dedicated finance workflows. These aren’t generic templates. They’re purpose-built for tasks analysts repeat every week: company comparables analysis, market sizing estimates, earnings call summarization, due diligence checklists. Each workflow guides you through the steps, with AI assistance at each stage.
You can customize them, save your versions, and share with your team. This turns ad-hoc analysis into repeatable, auditable processes. And for firms, that’s critical for consistency and compliance. The interface is designed for deep work—you can ask follow-up questions, drill into sources, and export findings seamlessly.
The Bigger Picture: Efficiency as the New Frontier
Step back for a second. What ties all these updates together? It’s not just new features. It’s a shared focus on efficiency—not just raw speed, but intelligent resource use. Gemini Embedding 2 uses MRL to do more with less compute. Mind Maps reduce cognitive load with better organization and flow.
Claude agents automate repetitive finance tasks without sacrificing judgment. ChatGPT in spreadsheets eliminates context-switching friction. Perplexity Computer consolidates data and workflows into one trusted environment. Each one respects your time, your budget, and your expertise—that’s the mark of mature AI.
It’s not about replacing humans. It’s about amplifying human potential. By handling the routine, the repetitive, and the resource-heavy. So you can focus on what only humans can do: strategy, creativity, and judgment. And the Matryoshka metaphor fits perfectly here.
Efficiency isn’t about stripping things down to the bare minimum. It’s about layering intelligence so each part serves its purpose optimally. The outer layer handles quick tasks with minimal overhead. The inner layers provide depth when the situation demands it. All nested together, working in harmony—that’s the future of AI systems.
Getting Started: Practical Next Steps
So, how do you put this into practice? Start with one area where efficiency hurts most. Is it slow semantic search? Try Gemini Embedding 2 with MRL truncation. Measure the latency and cost savings. Is your team drowning in spreadsheet tasks? Roll out the ChatGPT add-on to a pilot group.
Track time saved and error reduction. Are finance workflows eating up analyst time? Test one Claude agent template, like the valuation review. See how it integrates with your existing tools. The key is to start small, measure impact, and scale what works—and these tools are designed for incremental adoption.
You don’t need a big-bang overhaul. Just pick a pain point, apply the right AI update, and iterate. And remember: efficiency isn’t just about cost. It’s about velocity. Faster iteration means faster learning. Faster learning means better products and services. That’s how you win in a competitive market.
The Human Element: Why Tone and Trust Still Matter
One last thought. As AI gets more powerful, the human element becomes more critical. That’s why these updates emphasize explainability, customization, and collaboration. ChatGPT explains its spreadsheet formulas. Claude agents ask for human input on ambiguous cases. Mind Maps let you steer the AI with your prompts.
This isn’t accidental. It’s a recognition that trust is the foundation of adoption. People won’t use tools they don’t understand or can’t control. So the best AI systems don’t just perform well. They communicate clearly, adapt to user intent, and respect human oversight—that’s the professional touch.
It’s not about flashy demos. It’s about reliable, transparent, and respectful augmentation. And that’s what these updates deliver. When AI feels like a partner instead of a black box, adoption soars. And that’s where real business impact happens.
Looking Ahead: What’s Next for AI Efficiency?
If this wave is about flexible, efficient AI, what’s next? I’d bet on three trends. First: more models adopting MRL-like architectures. The efficiency gains are too compelling to ignore. Expect to see this pattern across embedding models, vision systems, and even LLMs as the industry matures.
Second: deeper workflow integration. AI won’t just be a tool you call. It’ll be woven into your applications, anticipating needs and acting proactively. Think: your spreadsheet add-on suggesting a better visualization before you ask. Or your RAG system auto-adjusting vector depth based on query complexity.
Third: stronger focus on domain-specific tuning. Generic AI is great. But finance, healthcare, legal—they have unique constraints and jargon. The next wave will be AI that speaks your industry’s language out of the box. Perplexity’s finance launch is a signal of this shift. Expect more vertical-specific AI suites soon.
Final Thoughts: Nesting Intelligence for Human Impact
So, let’s come full circle. Matryoshka dolls aren’t just a cute metaphor. They’re a design principle for the next generation of AI. Layered, adaptive, efficient. Gemini Embedding 2 shows how flexible representations can transform retrieval. Mind Maps demonstrate how better UX unlocks deeper thinking.
Claude agents prove that domain-specific automation can augment, not replace, expertise. ChatGPT in spreadsheets removes friction where it hurts most. Perplexity Computer for Finance brings trusted data and repeatable workflows together. Each update is a piece of a larger puzzle.
A puzzle where AI doesn’t just do more. It does what matters, with less waste, more clarity, and greater respect for human judgment. That’s the efficiency we should be chasing. Not just faster compute. But smarter, more purposeful intelligence. And with these updates, that promise is closer than ever.
So go ahead. Open that first doll. See what’s inside. Then build something remarkable with what you find.
Frequently Asked Questions (FAQs)
1. What is Matryoshka Representation Learning (MRL)?
Matryoshka Representation Learning (MRL) is an AI embedding technique where vectors are designed in nested layers, similar to Russian Matryoshka dolls. This allows developers to use smaller vector dimensions for faster tasks and larger dimensions for deeper analysis without losing semantic meaning. MRL improves AI efficiency by reducing storage costs and increasing retrieval speed.
2. How does Gemini Embedding 2 use Matryoshka Representation Learning?
Google’s Gemini Embedding 2 uses MRL by creating flexible embeddings that can be truncated based on task requirements. For example, developers can use smaller embeddings for quick candidate retrieval and full embeddings for final ranking in search or RAG systems. This helps optimize both performance and cost.
3. What are the benefits of MRL for vector databases?
MRL helps vector databases by:
- Reducing storage requirements
- Lowering infrastructure costs
- Improving query speed
- Eliminating the need for multiple embedding models
- Making AI systems more scalable
Businesses using vector databases for semantic search and recommendation systems can significantly cut operational expenses.
4. How does MRL improve RAG performance?
MRL improves Retrieval-Augmented Generation (RAG) systems by enabling faster document retrieval with smaller embeddings during the initial search phase. Larger embeddings can then be used for accurate re-ranking. This creates faster responses, better accuracy, and lower computational costs.
5. How can Gemini embeddings improve semantic search?
Gemini embeddings improve semantic search by understanding the meaning behind search queries rather than relying only on keywords. With MRL, businesses can optimize search performance by using flexible vector sizes for faster product recommendations, document search, and customer support systems.
6. What are Claude financial agents?
Claude financial agents are AI-powered workflow templates developed by Anthropic for financial services teams. These agents automate tasks like valuation reviews, investor pitch creation, financial reporting, compliance checks, and month-end closing processes while maintaining human oversight.
7. Can ChatGPT be used in Excel and Google Sheets?
Yes, OpenAI’s ChatGPT can now assist users inside spreadsheet platforms like Microsoft Excel and Google Sheets. Users can generate formulas, clean datasets, analyze financial data, automate repetitive spreadsheet tasks, and get real-time explanations without switching platforms.
8. What is Perplexity AI for finance teams?
Perplexity AI launched finance-focused tools that combine licensed financial datasets with AI workflows. These tools help analysts perform market research, company valuation, earnings analysis, due diligence, and financial reporting more efficiently.
9. What is the future of AI efficiency?
The future of AI efficiency will likely focus on:
- Smaller and smarter AI models
- Flexible embedding systems like MRL
- Industry-specific AI tools
- Workflow automation
- Lower infrastructure costs
- Better human-AI collaboration
Companies such as Google, OpenAI, Anthropic, and Perplexity AI are driving this shift.
10. Why is Matryoshka Representation Learning important for AI developers?
MRL is important because it helps developers build faster, cheaper, and more scalable AI systems. It is especially useful for applications involving semantic search, vector databases, recommendation engines, and retrieval-augmented generation systems.
Read more articles visit: techdg.in